原文:bit.ly/3wFqDy9
作者:Daniel
译者:王亮.NET 6 预览版 4 现已发布,其中包括对 ASP.NET Core 的许多新改进。
下面是此次预览版中 ASP.NET Core 的更新内容:
1 开始使用
要开始使用 .NET 6 Preview 4 中的 ASP.NET Core,请安装 .NET 6 SDK[1]。
如果你在 Windows 上使用 Visual Studio,我们建议安装 Visual Studio 2019 16.11 的最新预览版。如果你在 macOS 上,我们建议安装 Visual Studio 2019 for Mac 8.10 的最新预览版。
2 升级一个现有的项目
要将一个现有的 ASP.NET Core 应用程序从 .NET 6 Preview 3 升级到.NET 6 Preview 4。
将所有 Microsoft.AspNetCore. 引用包更新为 6.0.0-preview.4.。
更新所有 Microsoft.Extensions. 引用包更新为 6.0.0-preview.4.。
请参阅 .NET 6 中 ASP.NET Core 的完整中断变化列表[2]。
3 引入最小 API
在 .NET 6 中,我们为 Web 应用的托管和路由引入了最小 API。这为使用 .NET 构建第一个 Web 应用程序以及想要构建小型微服务和 HTTP API 的开发者打开了大门。这些精简的 API 提供了 ASP.NET MVC 的优点。
要尝试创建一个最小 API,请创建一个新的 ASP.NET Core 空 Web 应用。
dotnet new web -o MinApi
只需一个文件和几行代码,你现在就有一个功能齐全的 HTTP API。
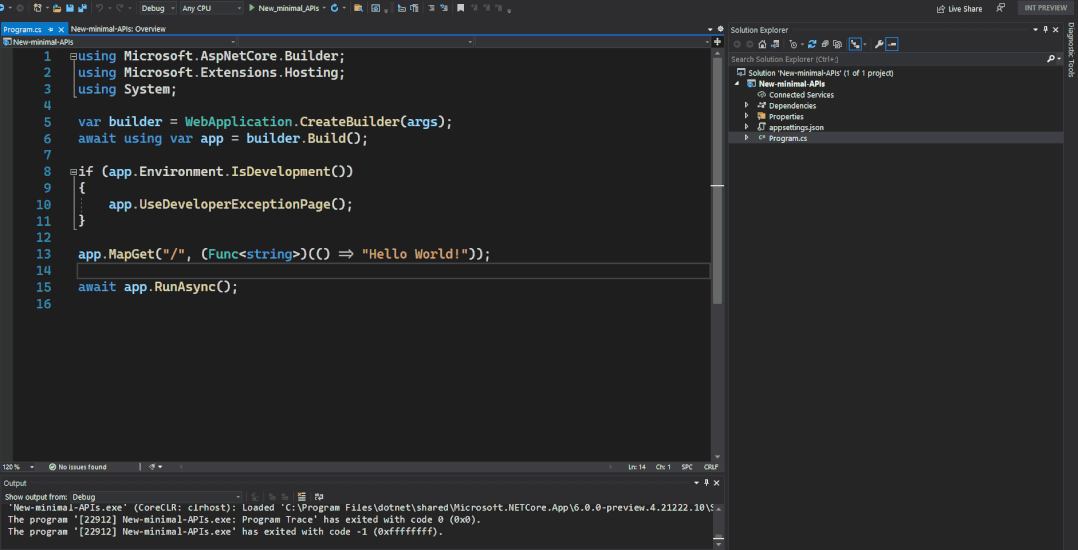
4 新的路由 API
新的路由 API 允许用户路由到任何类型的方法。这些方法可以使用类似控制器的参数绑定、JSON 格式化和 Action 结果。
之前(使用现有的 Map APIs):
app.MapGet("/", async httpContext =>
{
await httpContext.Response.WriteAsync("Hello World!");
});现在(使用新的 Map 重载):
app.MapGet("/", (Func<string>)(() => "Hello World!"));5 C# 10 的改进
这些 API 已经利用了较新的 C# 特性,如顶层语句。在今年晚些时候与 .NET 6 一起发布的 C# 10 中,体验将变得更好。例如,不再需要明确地把类型转换成 (Func
开发者从使用类和方法到使用 lambda,拥有和使用 MVC 控制器及属性操作一样的功能。
6 新的托管(hosting) API
新的空 Web 模板使用的是 .NET 6 Preview 4 中引入的新的托管模式。
var app = WebApplication.Create(args);
app.MapGet("/", (Func<string>)(() => "Hello World!"));
app.Run();你并不局限于只使用新的路由 API。下面是一个 Web 应用程序的例子,它被更新为使用新的托管模式,配置服务和添加中间件。
using Microsoft.AspNetCore.Builder;
using Microsoft.Extensions.DependencyInjection;
using Microsoft.Extensions.Hosting;
using Microsoft.OpenApi.Models;
var builder = WebApplication.CreateBuilder(args);
builder.Services.AddControllers();
builder.Services.AddSwaggerGen(c =>
{
c.SwaggerDoc("v1", new OpenApiInfo { Title = "Api", Version = "v1" });
});
var app = builder.Build();
if (app.Environment.IsDevelopment())
{
app.UseDeveloperExceptionPage();
app.UseSwagger();
app.UseSwaggerUI(c => c.SwaggerEndpoint("/swagger/v1/swagger.json", "Api v1"));
}
app.UseHttpsRedirection();
app.UseAuthorization();
app.MapControllers();
app.Run();新的托管 API 减少了配置和启动 ASP.NET 应用程序所需的模板数量。
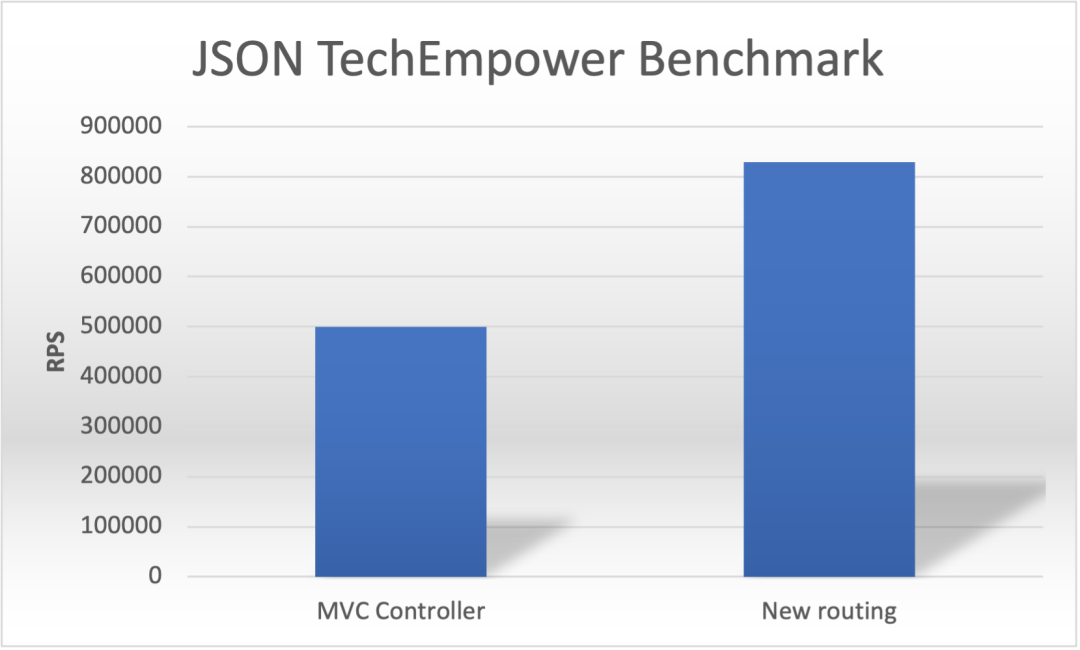
7 性能
这些新的路由 API 的开销比基于控制器的 API 少得多。使用新的路由 API,ASP.NET Core 能够在 TechEmpower[3] JSON 基准测试中达到约 80 万 RPS,而 MVC 则达到约 50 万 RPS。
异步流
ASP.NET Core 现在支持从控制器 Action 一直到响应的 JSON 格式化器的异步流。从 Action 中返回 IAsyncEnumerable,在发送之前不再在内存中缓冲响应内容。这有助于在返回可异步枚举的大型数据集时减少内存使用。
请注意,Entity Framework Core 提供了用于查询数据库的 IAsyncEnumerable 的实现。在 .NET 6 中,ASP.NET Core 对 IAsyncEnumerable 的支持有所改进,可以使 EF Core 与 ASP.NET Core 的使用更加高效。例如,下面的代码在发送响应前将不再把 Products 数据缓冲到内存中:
public IActionResult GetProducts()
{
return Ok(dbContext.Products);
}然而,如果你已经将 EF Core 设置为使用懒加载,这种新的行为可能会导致在数据被枚举时由于并发的查询执行而产生错误。你可以通过自己缓冲数据来恢复到以前的行为:
public async Task<IActionResult> Products()
{
return Ok(await dbContext.Products.ToListAsync());
}有关这一行为变化的更多细节,见相关公告[4]。
8 HTTP 日志中间件
HttpLogging 是一个新的内置中间件,可以记录 HTTP 请求和 HTTP 响应的信息,包括头信息和整个 Body。
public void Configure(IApplicationBuilder app, IWebHostEnvironment env)
{
app.UseHttpLogging();
}HttpLogging 中间件提供了以下日志:
HTTP 请求信息
普通属性
头信息
请求 Body
HTTP 响应信息
为了配置 HTTP 日志中间件,你可以在对 ConfigureServices() 的调用中指定 HttpLoggingOptions:
public void ConfigureServices(IServiceCollection services)
{
services.AddHttpLogging(logging =>
{
// Customize HTTP logging here.
logging.LoggingFields = HttpLoggingFields.All;
logging.RequestHeaders.Add("My-Request-Header");
logging.ResponseHeaders.Add("My-Response-Header");
logging.MediaTypeOptions.AddText("application/javascript");
logging.RequestBodyLogLimit = 4096;
logging.ResponseBodyLogLimit = 4096;
});
}这会在日志中产生新的带有 Microsoft.AspNetCore.HttpLogging.HttpLoggingMiddleware 类别的 HTTP 请求信息。
关于如何使用 HTTP 日志的更多信息,请看 HTTP 日志文档[5]。
9 使用 Kestrel 作为默认启动
对于在 .NET 6 Preview 4 中创建的所有新项目,我们已将默认的启动配置文件从 IIS Express 改为 Kestrel。在开发应用程序时,启动 Kestrel 的速度明显加快,并带来了更灵敏的体验。
IIS Express (ms) Kestrel (ms) % change
Debugging 4359 2772 36%
No debugging 1999 727 64%
IIS Express 仍然可以作为启动项,用于 Windows 认证或端口共享等情况。
10 IConnectionSocketFeature
IConnectionSocketFeature 功能使你能够访问与当前请求相关的底层接受 socket。它可以通过 HttpContext 上的 FeatureCollection 访问。
例如,下面的应用程序在接受 socket 上设置 LingerState 属性:
var builder = WebApplication.CreateBuilder(args);
builder.WebHost.ConfigureKestrel(serverOptions =>
{
serverOptions.ConfigureEndpointDefaults(listenOptions => listenOptions.Use((connection, next) =>
{
var socketFeature = connection.Features.Get<IConnectionSocketFeature>();
socketFeature.Socket.LingerState = new LingerOption(true, seconds: 10);
return next();
}));
});
var app = builder.Build();
app.MapGet("/", (Func<string>)(() => "Hello world"));
await app.RunAsync();11 改进单页应用(SPA)模板
略...(译注:文字太长,懒得翻译了,主要 VS 中的 SPA 模板我从来不用)
12.NET 热重载
最新的 Visual Studio 预览版对.NET Hot 热重载有一些初步的支持。你可能已经注意到在调试你的应用程序时,新的 Apply Code Changes 按钮和调试选项。
Apply Code Changes 按钮将用你所作的代码修改来更新正在运行的应用程序,甚至不需要保存。下面是一个更新 Counter 组件的例子,它的增量从 1 改为 2。请注意,一旦修改被应用,当前的计数不会丢失:
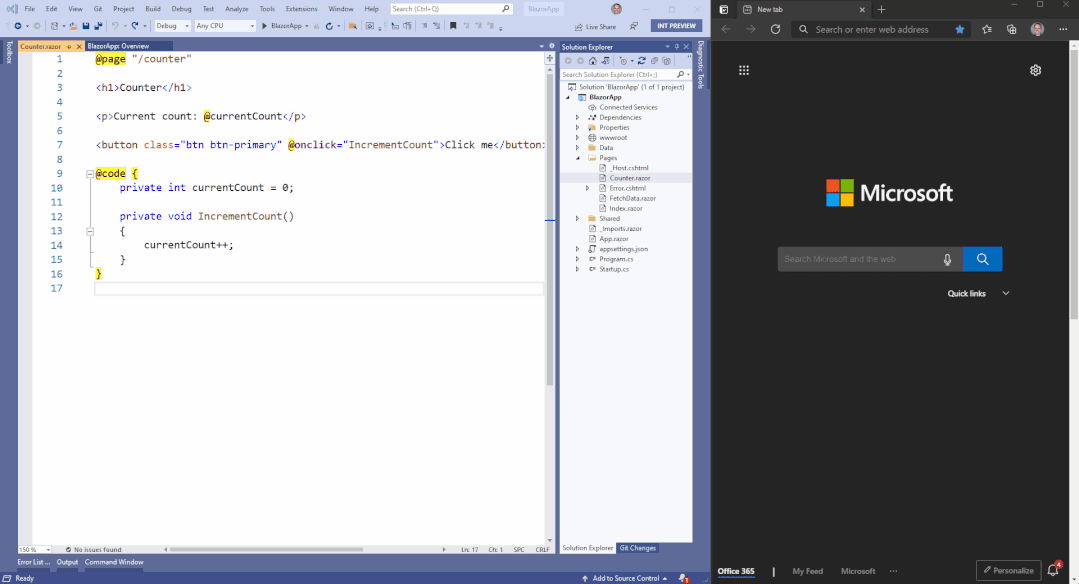
Visual Studio 中的 .NET 热重载支持仍在进行中,因此在 ASP.NET Core 应用程序中使用它时有一些限制:
你必须在连接调试器的情况下运行以应用更改。
代码修改只能应用于 C# 文件--还不支持对 Razor 文件(.razor, .cshtml)的修改。
已应用的更改还不能强制更新用户界面,因此需要手动触发用户界面更新。
目前不支持 Blazor WebAssembly 应用程序。
所有这些限制都在解决中,并将在未来的 Visual Studio 更新中得到解决。敬请关注!
如果你通过 dotnet watch 使用 .NET 热重载,修改将被应用于 ASP.NET Core 托管的 Blazor WebAssembly 应用程序。如果你刷新浏览器,修改也会重新应用到你的 Blazor WebAssembly 应用程序。
要了解更多关于.NET 热重载的信息,你可以在我们的博文中获得所有细节:介绍.NET 热重载[6]。
13 Razor 中的泛型约束
在 Razor 中使用 @typeparam 指令定义通用类型参数时,你现在可以使用标准的 C# 语法指定泛型约束。
@typeparam TEntity where TEntity : IEntity
14 Blazor 错误边界
Blazor 错误边界提供了一种方便的方式来处理组件层次结构中的异常情况。为了定义一个错误边界,使用新的 ErrorBoundary 组件来包裹一些现有的内容。只要一切运行顺利,ErrorBoundary 组件将渲染其子内容。如果一个未处理的异常被抛出,ErrorBoundary 会渲染一些错误 UI。
例如,我们可以像这样在默认 Blazor 应用程序的布局中添加一个错误边界:
<div class="main">
<div class="top-row px-4">
<a href="https://docs.microsoft.com/aspnet/" target="_blank" rel="noopener">
About
</a>
</div>
<div class="content px-4">
<ErrorBoundary> @Body </ErrorBoundary>
</div>
</div>该应用程序继续像以前一样运作,但现在我们的错误边界将处理未处理的异常。例如,我们可以更新 Counter 组件,在计数过大时抛出一个异常。
private void IncrementCount()
{
currentCount++;
if (currentCount > 10)
{
throw new InvalidOperationException("Current count is too big!");
}
}现在,如果我们过多地点击计数器,就会抛出一个未处理的异常,这将由我们的错误边界通过渲染一些默认的错误界面来处理。
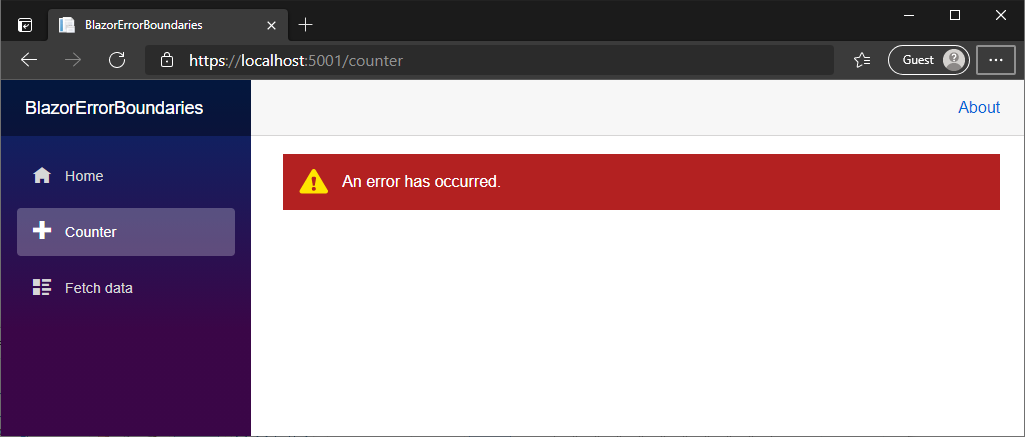
默认情况下,ErrorBoundary 组件为其错误内容渲染了一个带有 blazor-error-boundary CSS 类的空 div。这个默认界面的颜色、文本和图标都是在应用程序中使用 CSS 定义的,所以你可以自由地定制它们。你也可以通过设置 ErrorContent 属性来改变默认的错误内容。
<ErrorBoundary>
<ChildContent> @Body </ChildContent>
<ErrorContent>
<p class="my-error">Nothing to see here right now. Sorry!</p>
</ErrorContent>
</ErrorBoundary>因为我们在布局中定义了错误边界,一旦抛出一个异常,不管我们导航到哪个页面我们都能看到错误内容。一般来说,错误边界的范围最好比这更窄,但我们可以选择在随后的页面导航中通过调用错误边界的恢复方法将错误边界重置为非错误状态。
<ErrorBoundary @ref="errorBoundary">
@Body
</ErrorBoundary>
...
@code {
ErrorBoundary errorBoundary;
protected override void OnParametersSet()
{
// On each page navigation, reset any error state
errorBoundary?.Recover();
}
}15 Blazor WebAssembly 的 AOT 编译
Blazor WebAssembly 现在支持 AOT(ahead-of-time) 编译,你可以将你的 .NET 代码直接编译为 WebAssembly,以显著提高运行时性能。现在 Blazor WebAssemby 应用程序使用 WebAssembly 中实现的 .NET IL 解释器运行。由于 .NET 代码是被解释的,通常这意味着在 WebAssembly 上运行的 .NET 代码比在正常的.NET 运行时要慢得多。.NET WebAssembly AOT 编译通过将你的 .NET 代码直接编译成 WebAssembly 来解决这个性能问题。
AOT 编译你的 Blazor WebAssembly 应用程序,对于 CPU 密集型任务来说,其性能的提高是相当显著的。例如,下面的片段显示了使用相同的 Blazor WebAssembly 应用程序进行一些基本图像编辑的比较,首先使用解释器,然后是 AOT 编译。AOT 编译后的版本运行速度快了五倍以上。
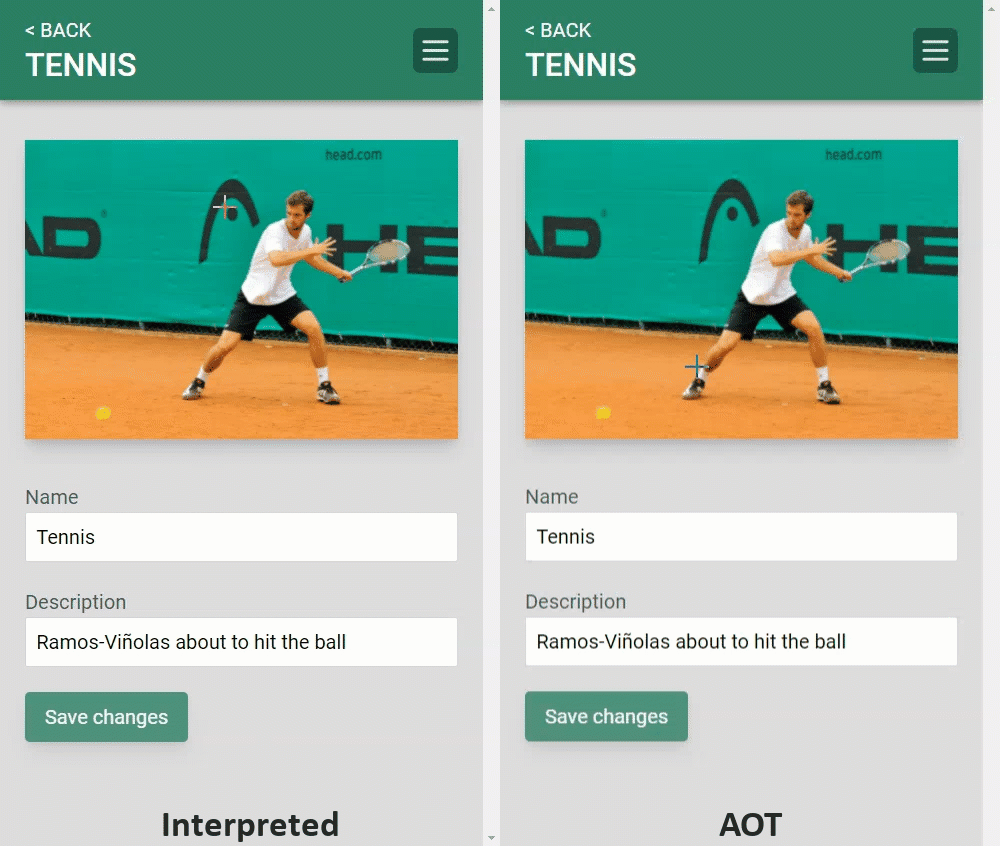
你可以在 GitHub 上查看这个 PictureFixer[7] 的代码。
.NET WebAssembly AOT 编译需要一个额外的构建工具,必须作为一个可选的 .NET SDK 工作负载来安装才能使用。要安装 .NET WebAssembly 构建工具,请运行以下命令:
dotnet workload install microsoft-net-sdk-blazorwebassembly-aot
为了在你的 Blazor WebAssembly 项目中启用 WebAssembly AOT 编译,在你的项目文件中添加以下属性:
然后 AOT 将你的应用程序编译成 WebAssembly,发布应用程序。使用 Release 配置发布将确保 .NET IL 链接也被运行,以减少发布应用程序的大小。
dotnet publish -c Release
WebAssembly AOT 编译只在项目发布时进行。当项目在开发过程中运行时,它并不使用。这是因为 WebAssembly AOT 编译可能需要一段时间。
AOT 编译的 Blazor WebAssembly 应用程序的大小通常比作为 .NET IL 的应用程序要大。在我们的测试中,大多数 AOT 编译的 Blazor WebAssembly 应用程序大约大2倍,不过这取决于具体的应用程序。这意味着,使用 WebAssembly 的 AOT 编译,可以用加载时间的性能换取运行时间的性能。这种权衡是否值得,取决于你的应用程序。
16 .NET MAUI Blazor 应用
Blazor 能够用 .NET 构建客户端 Web UI,但有时你需要的东西比 Web 平台提供的更多。有时你需要完全访问设备的本地功能。现在,你可以在 .NET MAUI 应用程序中托管 Blazor 组件,以使用 Web UI 构建跨平台的本地应用程序。这些组件在.NET 进程中原生运行,并使用本地互操作通道向嵌入式 Web 视图控件渲染 Web UI。这种混合方法为你提供了本地和网络的优点。你的组件可以通过 .NET 平台访问本地功能,并呈现标准的 Web UI。.NET MAUI Blazor 应用程序可以运行在任何 .NET MAUI 可以运行的地方(Windows、Mac、iOS 和 Android),尽管我们对 .NET 6的主要关注是在桌面场景。
要创建一个 .NET MAUI Blazor 应用程序,你首先需要在开发机器上配置 .NET MAUI。最简单的方法是使用 maui-check 工具。要安装 maui-check 工具,请运行:
dotnet tool install -g Redth.Net.Maui.Check
然后运行 maui-check 来获取 .NET MAUI 工具和依赖。有关开始使用 .NET MAUI 的其他信息,请参考 GitHub 上的 wiki 文档。
一旦一切安装完毕,使用新的项目模板创建一个 .NET MAUI Blazor 应用程序:
dotnet new maui-blazor -o MauiBlazorApp
你也可以使用 Visual Studio 创建一个 .NET MAUI Blazor 应用程序:
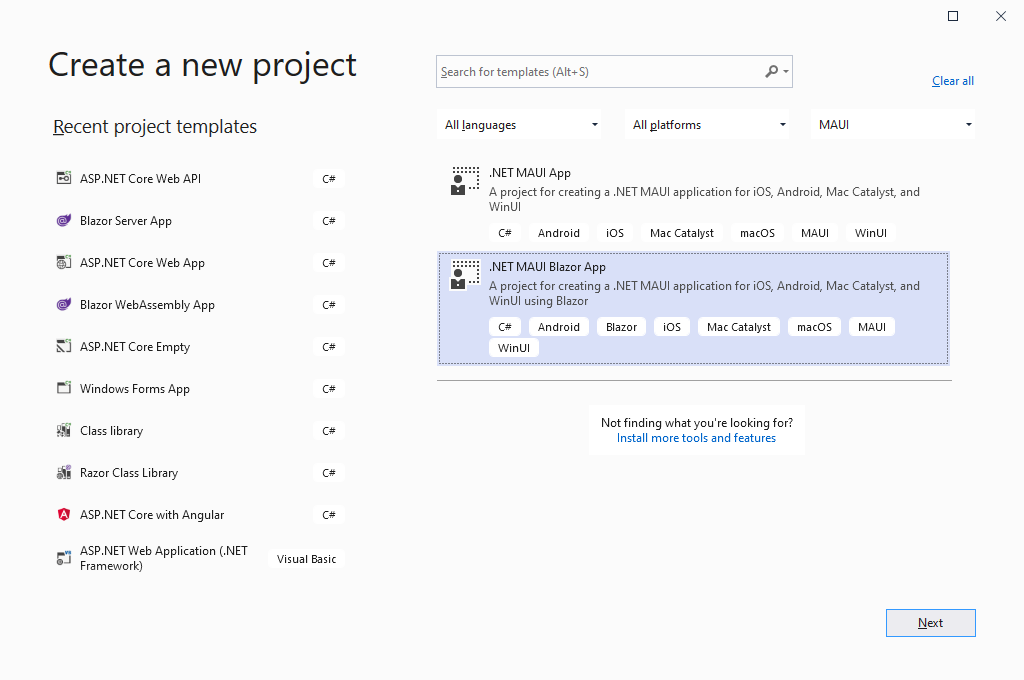
.NET MAUI Blazor 应用程序是 .NET MAUI 应用程序,它使用 BlazorWebView 控件将 Blazor 组件渲染到一个嵌入式 Web 视图中。应用程序的代码和逻辑位于 MauiApp 项目中,该项目被设置为多目标 Android、iOS 和 Mac Catalyst。MauiApp.WinUI3 项目用于为 Windows 构建,而 MauiApp.WinUI3(Package) 项目则用于为 Windows 生成 MSIX 包。最终,我们希望将对 Windows 的支持合并到主应用程序项目中,但现在这些独立的项目是必要的。
在 MauiApp 项目的 MainPage.xaml 中设置了 BlazorWebView 控件:
<b:BlazorWebView HostPage="wwwroot/index.html">
<b:BlazorWebView.RootComponents>
<b:RootComponent Selector="#app" ComponentType="{x:Type local:Main}" />
</b:BlazorWebView.RootComponents>
</b:BlazorWebView>该应用程序的根 Blazor 组件在 Main.razor 中。其余的 Blazor 组件都在 Pages 和 Shared 目录下。请注意,这些组件与默认 Blazor 模板中使用的组件相同。你可以在你的应用程序中使用现有的 Blazor 组件,而不用改变代码,或者引用包含这些组件的现有类库或包。应用程序的静态资源在 wwwroot 文件夹中。
17 Windows
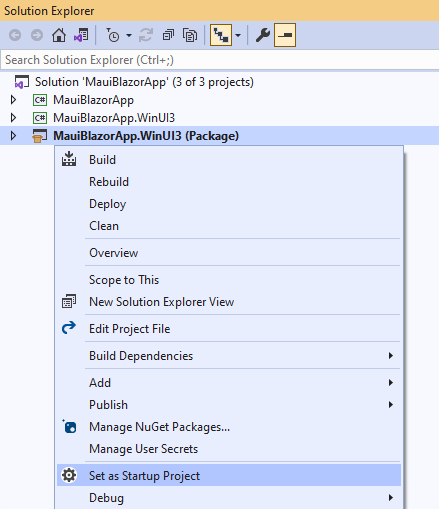
要在 Windows 下运行该应用程序,你需要使用 Visual Studio 构建和运行。
选择 MauiBlazorApp.WinUI3(Package) 项目作为你的启动项目:
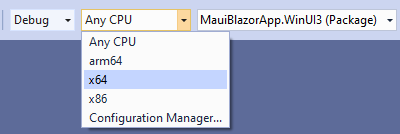
同时为目标平台选择 x64:
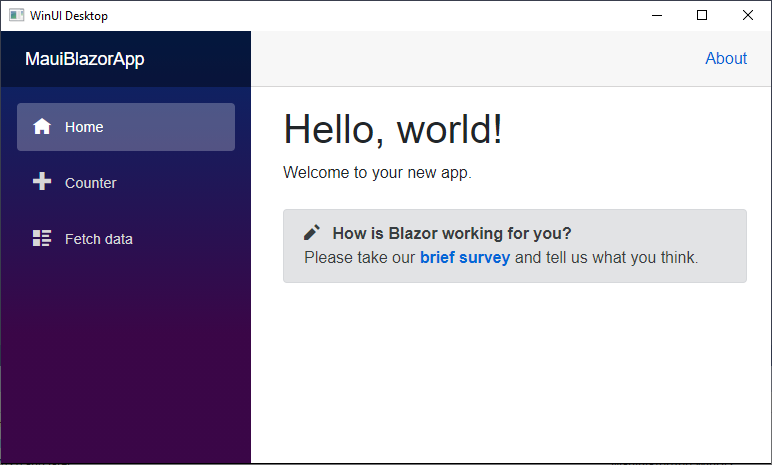
然后你可以按 F5 或 Ctrl+F5,使 WinUI 应用作为本地 Windows 桌面应用运行。
18 Android
要在 Android 上运行该应用程序,首先使用 Android SDK 或 Android 设备管理器启动 Android 模拟器。
然后使用以下命令从 CLI 运行该应用程序:
dotnet build MauiBlazorApp -t:Run -f net6.0-android
要从 Visual Studio 在 Android 上运行,选择 MauiBlazorApp 项目作为启动项目:
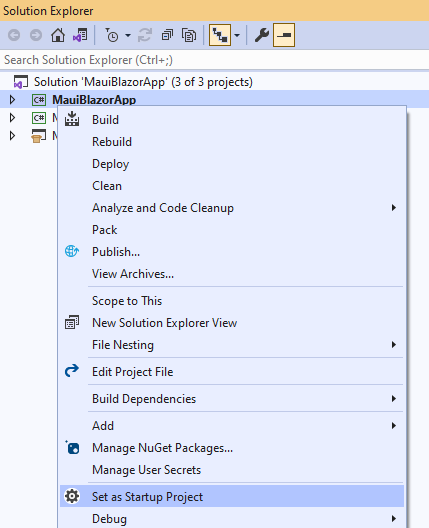
然后在运行按钮下拉菜单中选择 net6.0-android 作为目标框架:
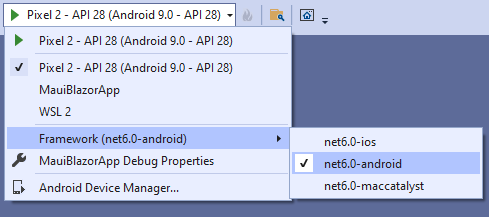
然后你可以点击 F5 或 Ctrl+F5,使用安卓模拟器运行该应用程序:
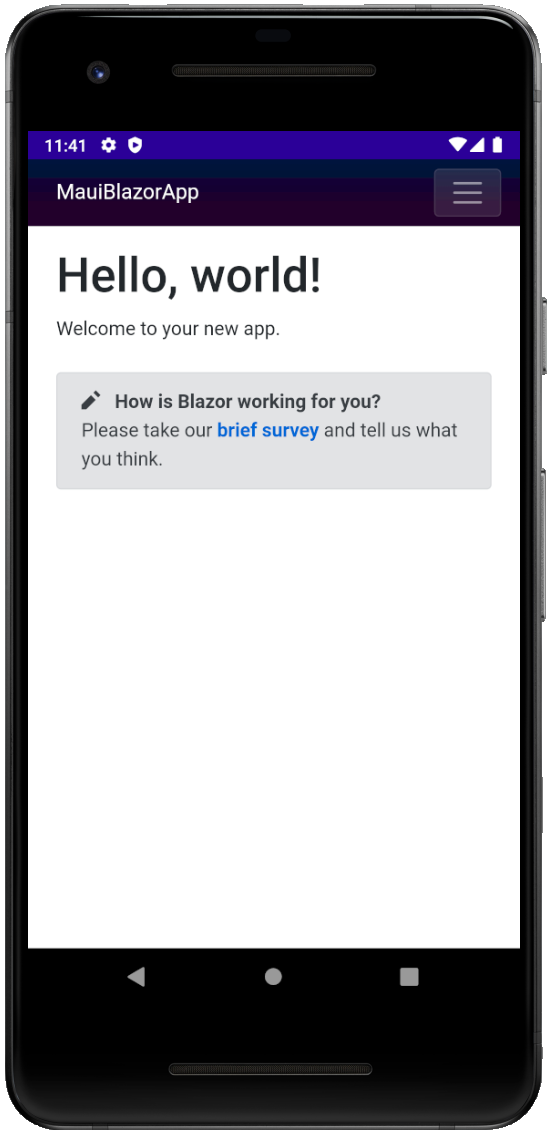
19 iOS 和 Mac Catalyst
译注:Mac Catalyst 是一个帮助开发者将 iOS 应用移植到 macOS 上的服务。
要运行 iOS 或 Mac Catalyst 的应用程序,你需要使用一个运行 Big Sur 的 macOS 开发环境。你目前不能从 Windows 开发环境中运行 iOS 或 Mac Catalyst 的应用程序,尽管我们确实期望 .NET MAUI 将支持使用连接的 Mac 构建代理或使用热重启在连接的设备上运行 iOS 应用程序。
要运行 iOS 和 Mac Catalyst 的应用程序,请使用以下命令:
dotnet build MauiBlazorApp -t:Run -f net6.0-ios
dotnet build MauiBlazorApp -t:Run -f net6.0-maccatalyst
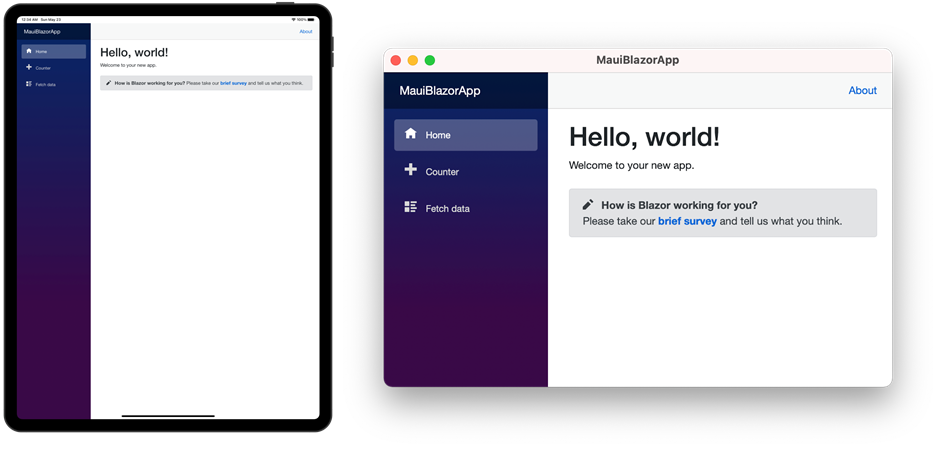
在这个版本中,.NET MAUI Blazor 应用程序有一些已知的限制:
组件范围内的 CSS 文件(.razor.css)还不能在主 .NET MAUI 项目中使用。这将在未来的更新中得到修复。
了解更多关于 .NET 6 Preview 4 中 .NET MAUI 的新内容[8]。
20 其他性能改进
略...(注:这部分列举了一些社区贡献的提高性能的 PR,没啥可翻译的,感兴趣的同学可以直接在英文原文点击链接查看。)
21 提供反馈
我们希望你喜欢此次 .NET 6 中的 ASP.NET Core 预览版。我们很想听听你对这个版本的体验。在 GitHub[9] 上提交 Issue,让我们知道你的想法。
感谢你尝试使用 ASP.NET Core!
文中链接:
[1]. https://dotnet.microsoft.com/download/dotnet/6.0
[2]. https://docs.microsoft.com/dotnet/core/compatibility/6.0#aspnet-core
[3]. https://www.techempower.com/benchmarks/
[4]. https://github.com/aspnet/Announcements/issues/463
[5]. https://docs.microsoft.com/aspnet/core/fundamentals/http-logging
[6]. https://aka.ms/build2021-hotreload
[7]. https://aka.ms/picture-fixer
[8]. https://devblogs.microsoft.com/dotnet/announcing-net-maui-preview-4
[9]. https://github.com/dotnet/aspnetcore/issues